[python] 벡터화 연산(vectorized operation) 리뷰
벡터화?란 수학적인 의미론 행렬을 세로 벡터로 만드는 선형 변환의 의미이고
*참고 : https://ko.wikipedia.org/wiki/%EB%B2%A1%ED%84%B0%ED%99%94
데이터 분석 관점에선 배열이나 행렬과 같은 다차원 데이터 구조에 대해
요소 별 연산을 한번에 처리하는 방법입니다.
그럼 왜 할까요?
효율적인 연산 처리를 위해 벡터화 연산을 사용합니다.
만약 전체 데이터를 반복해서 무언가를 만들어야 한다면 보통 for문으로 각 요소의 연산을 반복합니다.
작은 사이즈의 데이터는(몇 MB?) 큰 문제가 없지만 데이터의 사이즈가 커지면
해당 코드를 실행시키는데 메모리나 CPU, 네트워크 사용이 과다해져서 프로그램 실행에 문제가 생기게 됩니다.
for문과 달리 벡터화 연산은 모든 배열(요소)을 한 번에 연산하여 효율적으로 데이터를 처리할 수 있습니다.
이해를 돕기 위해 두 리스트의 합을 구한다면 1. for문, 2. 벡터화 연산 두 가지로 구할 수 있습니다.
- for 문

a의 각 값과 b의 각 값을 더한다고 했을 때 for문을 이용하여 더할 경우 위에서부터 순차적으로 더하게 됩니다.
1 + 2 -> 3 + 4 -> 5 + 6
a = [1, 3, 5, 7]
b = [2, 4, 6, 8]
results = [x + y for x, y in zip(a, b)]
2. 벡터화 연산

벡터화 연산을 하게 될 경우 각 요소 별로 한 번에 더하게 됩니다.
1+2
3+4
5+6
a = np.array([1, 3, 5, 7])
b = np.array([2, 4, 6, 8])
results = a + b즉 벡터화 연산이 더 간결하고 효율적으로 데이터를 처리할 수 있습니다.
파이썬에선 numpy가 벡터화 연산을 지원하며 아래 예시를 통해 확인 가능합니다.
<numpy.vectorize>
np.vectorize는 스칼라 값들을 벡터화하여 스칼라 요소들을 한 번에 연산 처리할 수 있게 지원하는 클래스입니다.
출처 : https://numpy.org/doc/stable/reference/generated/numpy.vectorize.html
numpy.vectorize — NumPy v1.25 Manual
Generalized universal function signature, e.g., (m,n),(n)->(m) for vectorized matrix-vector multiplication. If provided, pyfunc will be called with (and expected to return) arrays with shapes given by the size of corresponding core dimensions. By default,
numpy.org
샘플 함수를 정의한 다음 np.vectorize에 해당 함수를 넣게 되면
def myfunc(a, b):
if a > b: #a가 b보다 크면 a+b를 생성
return a + b
else: #반대면 크면 a*b를 생성
return a * bvfunc = np.vectorize(myfunc)
vfunc([1, 2, 3, 4], 2)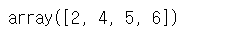
<numpy.where>
np.where는 주어진 조건에 따라 맞으면 x, 틀리면 y를 반환하는 클래스입니다.
출처 : https://numpy.org/doc/stable/reference/generated/numpy.where.html#numpy-where
numpy.where — NumPy v1.25 Manual
Return elements chosen from x or y depending on condition. Note When only condition is provided, this function is a shorthand for np.asarray(condition).nonzero(). Using nonzero directly should be preferred, as it behaves correctly for subclasses. The rest
numpy.org
아래 코드는 a라는 행렬을 만들고 a가 4보다 작을 때는 a를 반환하고 아닐 경우 -1을 반환하게 됩니다.
a = np.array([[0, 1, 2], [0, 2, 4], [0, 3, 6]])
np.where(a < 4, a, -1) # -1 is broadcast아래와 같은 결과 값이 나오게 됩니다.

np.where은 데이터프레임을 가공할 때도 많이 사용합니다.
참고로 아래 코드는 특정 행이 주어진 조건을 만족할 때 df['new_col']에 value를 할당해라는 의미인데
np.where과 동일하게 벡터화 연산 처리합니다.
df.loc[condition, 'new_col'] = value
Pandas 또한 1차원(series), 2차원(dataframe) 배열을 가지기에 벡터화 연산을 지원합니다.
예시로 np.where을 데이터프레임에 적용할 수 있습니다.
df['new_col'] = np.where(condition, TRUE, FALSE)
결론적으로 간결하고 효율적인 코드를 만들고 싶다면 벡터화 연산을 고려하면 좋을 듯 합니다.